
Введение в современные методы прогнозирования
Финансовые рынки представляют собой одну из самых сложных систем для прогнозирования, характеризующуюся высокой волатильностью, нелинейными зависимостями и постоянно меняющимися паттернами. Традиционные статистические методы, такие как ARIMA и экспоненциальное сглаживание, часто оказываются недостаточными для захвата сложной динамики современных финансовых инструментов. В последние годы методы машинного обучения, особенно глубокие нейронные сети, продемонстрировали значительный потенциал в моделировании временных рядов с высокой степенью нелинейности.
Ключевым вызовом остается способность моделей адаптироваться к беспрецедентным рыночным событиям — ситуациям, которые не имеют аналогов в исторических данных. Пандемия COVID-19, геополитические кризисы и технологические революции создают рыночные условия, которые выходят за рамки обучающих выборок большинства моделей. Это требует разработки более гибких и робастных подходов к прогнозированию, способных обобщать знания на новые, ранее не встречавшиеся ситуации.
В данной статье мы рассмотрим три основных класса архитектур глубокого обучения: рекуррентные нейронные сети с долгой краткосрочной памятью (LSTM), трансформерные модели с механизмами внимания и ансамблевые методы, объединяющие предсказания множества базовых моделей. Каждый из этих подходов имеет свои преимущества и ограничения в контексте финансового прогнозирования.
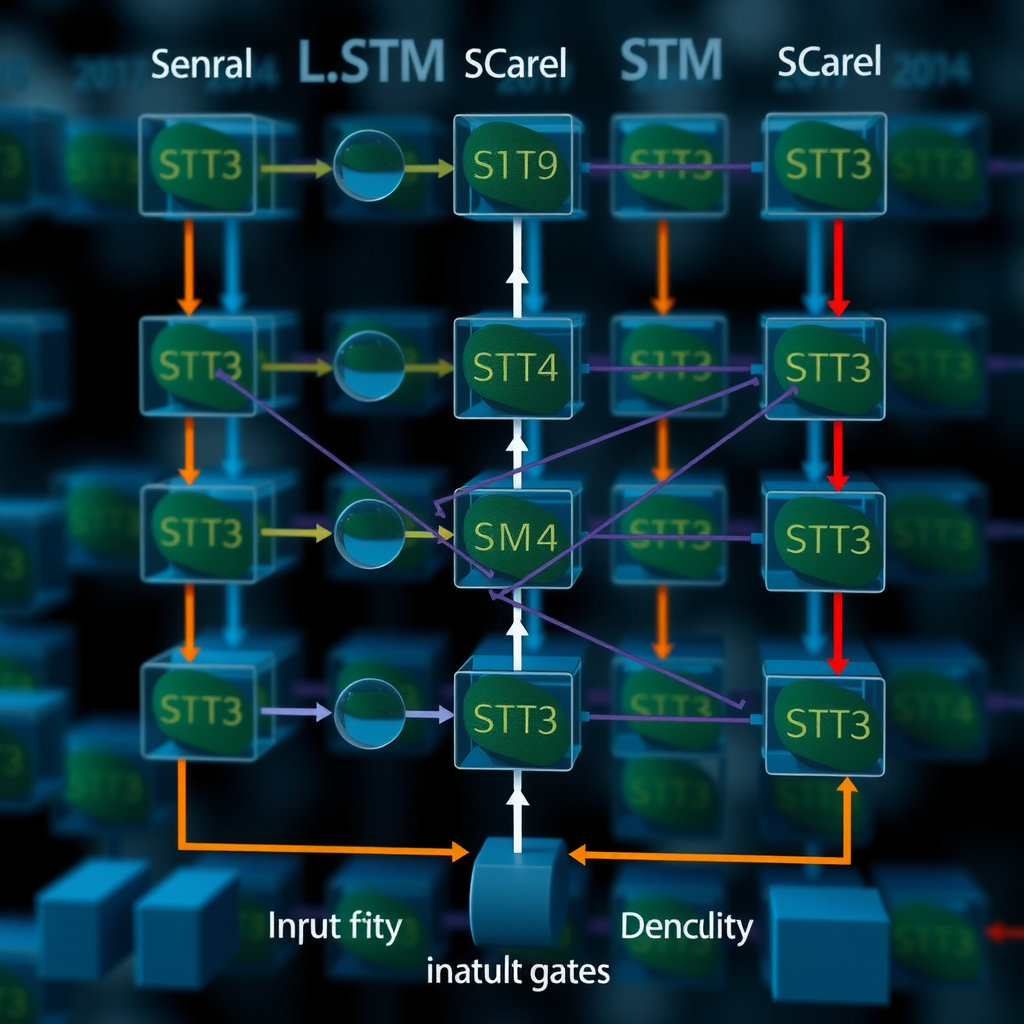
LSTM-сети: архитектура и применение
Сети долгой краткосрочной памяти (Long Short-Term Memory, LSTM) представляют собой специализированный тип рекуррентных нейронных сетей, разработанный для решения проблемы исчезающего градиента при обучении на длинных последовательностях. В контексте финансовых временных рядов LSTM-сети способны захватывать как краткосрочные флуктуации, так и долгосрочные тренды, что делает их особенно привлекательными для задач прогнозирования цен активов.
Архитектура LSTM-ячейки включает три основных компонента: входной вентиль (input gate), вентиль забывания (forget gate) и выходной вентиль (output gate). Входной вентиль определяет, какая информация из текущего входа должна быть добавлена в состояние ячейки. Вентиль забывания контролирует, какая часть предыдущего состояния должна быть сохранена или отброшена. Выходной вентиль регулирует, какая информация из состояния ячейки должна быть передана на следующий слой или использована для формирования выходного сигнала.
Ключевые преимущества LSTM в финансовом прогнозировании
- Способность моделировать долгосрочные зависимости в данных без потери информации
- Гибкость в обработке последовательностей переменной длины
- Устойчивость к проблеме исчезающего градиента при обучении
- Возможность интеграции с другими архитектурами для создания гибридных моделей
При применении LSTM к финансовым данным критически важна правильная подготовка входных признаков. Помимо исторических цен, модели часто включают технические индикаторы (скользящие средние, RSI, MACD), объемы торгов, макроэкономические показатели и даже альтернативные данные, такие как настроения в социальных сетях. Нормализация и стандартизация данных играют ключевую роль в стабильности обучения и качестве предсказаний.
Одним из практических подходов является использование многослойных LSTM-архитектур, где каждый последующий слой обучается извлекать более абстрактные представления из выходов предыдущего слоя. Типичная конфигурация может включать 2-3 LSTM-слоя с 128-256 нейронами в каждом, за которыми следуют полносвязные слои для финального предсказания. Регуляризация через dropout (обычно 0.2-0.3) между слоями помогает предотвратить переобучение.

Трансформерные архитектуры и механизмы внимания
Трансформеры, первоначально разработанные для задач обработки естественного языка, в последние годы показали впечатляющие результаты в моделировании временных рядов. Ключевым отличием от рекуррентных архитектур является механизм самовнимания (self-attention), который позволяет модели напрямую взвешивать важность различных временных точек при формировании предсказания, независимо от их удаленности в последовательности.
Механизм внимания работает путем вычисления трех матриц для каждого элемента последовательности: запросов (queries), ключей (keys) и значений (values). Веса внимания определяются через скалярное произведение запросов и ключей, нормализованное функцией softmax. Эти веса затем применяются к значениям для получения взвешенного представления, которое учитывает релевантность всех элементов последовательности.
В финансовом контексте трансформеры особенно эффективны для захвата сложных взаимодействий между различными временными периодами. Например, модель может научиться придавать больший вес данным из периодов с аналогичной рыночной волатильностью или макроэкономическими условиями. Это позволяет создавать более контекстно-зависимые предсказания по сравнению с традиционными подходами.
Одним из вызовов при применении трансформеров к финансовым данным является их вычислительная сложность, которая квадратично растет с длиной последовательности. Для решения этой проблемы были разработаны различные модификации, такие как Sparse Transformers, Linformer и Performer, которые снижают вычислительные требования при сохранении способности моделировать долгосрочные зависимости.
Позиционное кодирование и временные эмбеддинги
Поскольку трансформеры не имеют встроенного понятия порядка элементов в последовательности, критически важно добавление позиционного кодирования. В финансовых приложениях стандартное синусоидальное позиционное кодирование часто дополняется или заменяется специализированными временными эмбеддингами, которые учитывают календарные эффекты (день недели, месяц, квартал) и циклические паттерны рынка.
Исследования показывают, что включение информации о времени суток, дне недели и сезонности может значительно улучшить качество предсказаний, особенно для высокочастотных торговых стратегий. Некоторые архитектуры используют обучаемые эмбеддинги для различных временных масштабов, позволяя модели самостоятельно определять наиболее релевантные временные паттерны.
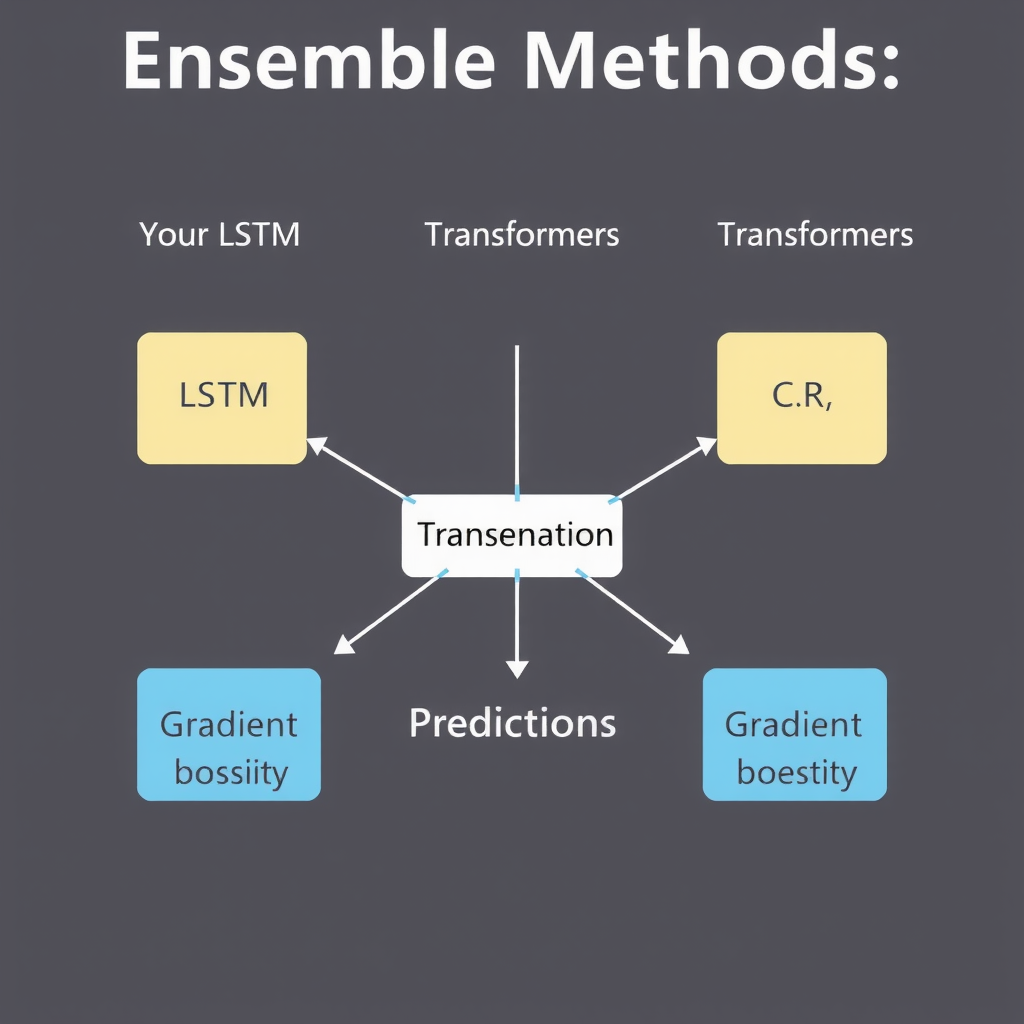
Ансамблевые методы и агрегация предсказаний
Ансамблевые методы объединяют предсказания нескольких базовых моделей для получения более робастных и точных результатов. В финансовом прогнозировании ансамбли особенно ценны, поскольку они могут компенсировать слабости отдельных моделей и снижать влияние выбросов или аномальных рыночных событий. Существует несколько основных подходов к построению ансамблей: бэггинг, бустинг и стекинг.
Бэггинг (bootstrap aggregating) создает множество версий обучающего набора через случайную выборку с возвращением и обучает отдельную модель на каждой версии. Финальное предсказание формируется путем усреднения (для регрессии) или голосования (для классификации) предсказаний всех моделей. Этот подход эффективно снижает дисперсию предсказаний и делает модель более устойчивой к шуму в данных.
Бустинг, напротив, обучает модели последовательно, где каждая последующая модель фокусируется на исправлении ошибок предыдущих. Градиентный бустинг, особенно в реализациях XGBoost и LightGBM, стал стандартом де-факто для многих финансовых приложений благодаря своей способности эффективно обрабатывать табличные данные и автоматически выявлять важные признаки.
Стратегии комбинирования моделей
- Простое усреднение: равные веса для всех моделей
- Взвешенное усреднение: веса пропорциональны производительности на валидационном наборе
- Стекинг: мета-модель обучается оптимально комбинировать предсказания базовых моделей
- Динамическое взвешивание: веса адаптируются в зависимости от текущих рыночных условий
Стекинг представляет собой более сложный подход, где предсказания базовых моделей используются как входные признаки для мета-модели, которая обучается оптимально их комбинировать. Это позволяет системе автоматически определять, какие модели более надежны в различных рыночных режимах. Например, LSTM-модели могут быть более точными в периоды плавных трендов, в то время как трансформеры лучше справляются с резкими изменениями волатильности.
Гибридные архитектуры
Современные исследования все чаще фокусируются на гибридных архитектурах, которые объединяют преимущества различных подходов. Например, CNN-LSTM модели используют свёрточные слои для извлечения локальных паттернов из временных рядов, после чего LSTM-слои моделируют долгосрочные зависимости. Трансформеры могут быть интегрированы с рекуррентными сетями для создания архитектур, которые эффективно обрабатывают как локальные, так и глобальные временные паттерны.

Техники валидации моделей
Валидация моделей прогнозирования временных рядов требует особого подхода, отличного от стандартной кросс-валидации, используемой для независимых наблюдений. Ключевым принципом является сохранение временного порядка данных: модель должна обучаться только на прошлых данных и тестироваться на будущих. Нарушение этого принципа приводит к утечке информации (data leakage) и завышенным оценкам производительности.
Временное разделение (time-series split) является базовым методом валидации, где данные последовательно делятся на обучающую и тестовую выборки с сохранением хронологического порядка. Более продвинутый подход — скользящее окно (rolling window), где модель переобучается на каждом новом временном интервале, что позволяет оценить её способность адаптироваться к изменяющимся рыночным условиям.
Для финансовых приложений критически важно тестирование на out-of-sample данных, которые не только следуют хронологически после обучающей выборки, но и включают различные рыночные режимы: бычьи и медвежьи рынки, периоды высокой и низкой волатильности, кризисные события. Модель, которая хорошо работает только в одном режиме, имеет ограниченную практическую ценность.
Метрики оценки качества
Выбор метрик оценки должен соответствовать конкретной задаче и бизнес-целям. Для задач регрессии стандартными метриками являются средняя абсолютная ошибка (MAE), среднеквадратичная ошибка (RMSE) и средняя абсолютная процентная ошибка (MAPE). Однако в финансовом контексте часто более релевантны метрики, основанные на направлении движения цены (directional accuracy) или прибыльности торговых стратегий, построенных на предсказаниях модели.
Коэффициент Шарпа, максимальная просадка и коэффициент Сортино являются важными метриками для оценки риск-скорректированной доходности стратегий, основанных на прогнозах модели. Эти метрики учитывают не только точность предсказаний, но и их практическую применимость в реальных торговых условиях, включая транзакционные издержки и проскальзывание.
Ограничения исторических данных
Фундаментальное ограничение всех моделей машинного обучения заключается в их зависимости от исторических данных для обучения. Финансовые рынки, однако, характеризуются структурными изменениями, которые делают прошлые паттерны менее релевантными для будущих предсказаний. Технологические инновации, изменения в регулировании, появление новых классов активов и эволюция рыночной микроструктуры — все это создает условия, которые могут не иметь аналогов в обучающих данных.
Проблема "черных лебедей" — редких, но высокоимпактных событий — представляет особый вызов для моделей прогнозирования. По определению, такие события не могут быть адекватно представлены в исторических данных, и модели, обученные на прошлых данных, систематически недооценивают вероятность их возникновения. Финансовый кризис 2008 года, пандемия COVID-19 и другие системные шоки демонстрируют ограничения чисто data-driven подходов.
Концепция "режимных сдвигов" (regime shifts) описывает ситуации, когда фундаментальные характеристики рынка изменяются таким образом, что исторические паттерны становятся нерелевантными. Например, переход от низкопроцентной к высокопроцентной среде может радикально изменить корреляции между классами активов и эффективность различных торговых стратегий. Модели должны быть способны обнаруживать такие сдвиги и адаптироваться к новым условиям.
Стратегии работы с ограничениями данных
- Регулярное переобучение моделей на свежих данных для адаптации к изменяющимся условиям
- Использование ансамблей моделей, обученных на различных временных периодах
- Интеграция экспертных знаний и фундаментального анализа для дополнения data-driven подходов
- Разработка механизмов обнаружения аномалий и режимных сдвигов
- Применение методов transfer learning для переноса знаний между связанными рынками
Байесовские подходы и квантификация неопределенности
Байесовские нейронные сети предлагают принципиальный подход к квантификации неопределенности в предсказаниях. Вместо точечных оценок эти модели предоставляют распределения вероятностей для предсказываемых значений, что позволяет явно моделировать эпистемическую неопределенность (связанную с ограниченностью данных) и алеаторическую неопределенность (присущую стохастической природе рынков).
Практическая реализация байесовских подходов часто использует методы вариационного вывода или Monte Carlo Dropout для аппроксимации апостериорных распределений параметров модели. Это позволяет генерировать множество предсказаний для каждого входа, формируя доверительные интервалы, которые расширяются в периоды высокой неопределенности и сужаются, когда модель более уверена в своих предсказаниях.
Заключение и перспективы развития
Продвинутые методы прогнозирования, основанные на глубоком обучении, представляют собой мощный инструментарий для анализа финансовых временных рядов. LSTM-сети, трансформерные архитектуры и ансамблевые методы демонстрируют способность захватывать сложные нелинейные паттерны и долгосрочные зависимости в данных. Однако важно признавать фундаментальные ограничения этих подходов, особенно в контексте беспрецедентных рыночных событий.
Будущее финансового прогнозирования, вероятно, будет лежать в интеграции data-driven методов с экспертными знаниями, фундаментальным анализом и причинно-следственным моделированием. Гибридные системы, которые комбинируют статистическую мощь машинного обучения с структурированным пониманием экономических механизмов, имеют потенциал преодолеть некоторые ограничения чисто эмпирических подходов.
Развитие методов transfer learning и meta-learning открывает новые возможности для обобщения знаний между различными рынками и временными периодами. Эти подходы позволяют моделям быстрее адаптироваться к новым условиям, используя знания, полученные из связанных задач. Кроме того, растущая доступность альтернативных данных — от спутниковых изображений до анализа настроений в социальных сетях — предоставляет новые источники информации для улучшения качества прогнозов.
Критически важным остается вопрос интерпретируемости моделей. Финансовые институты и регуляторы все чаще требуют объяснимости решений, принимаемых на основе алгоритмов машинного обучения. Разработка методов, которые сочетают высокую предсказательную способность с интерпретируемостью, является активной областью исследований и будет определять практическое применение этих технологий в ближайшие годы.